In our previous article, we showed that neural networks are vulnerable to carefully crafted adversarial attacks, i.e. attacks based on minor modifications of the input.
While those perturbations are often invisible to a human observer or perceived as noise that does not influence the recognition, they can fool even the most successful state-of-the-art neural network based systems. Thus, it is of great importance to be able to defend against such attacks, especially in safety-critical environments.
Multiple techniques have been proposed over the last years to achieve this, including but not limited to: adversarial training, image preprocessing or transformation and feature denoising.
The most popular defense strategy is adversarial training. In this method, images are adversarially attacked with a chosen approach (for example fast gradient sign method described in our previous post) and perturbed examples are introduced to the model during the training process so that it learns to classify them correctly [1,2]. Another group of methods involves image preprocessing. Since perturbations are often perceived as noise to a human observer, several approaches based on transforming or preprocessing input images before they are fed to the neural network have been introduced [3,4].
Additionally, Xie et al. [5] proposed feature denoising as a method of defense against adversarial attacks based on the observation that perturbations in images cause noise in the feature maps.
In today’s article, we will present two state-of-the-art methods of defense against adversarial attacks.
Adversarial training
Adversarial training was first introduced by Szegedy et al. [1] and it is currently the most popular technique of defense against adversarial attacks. This method involves training a network on a mixture of adversarial and clean examples. Goodfellow et al. [6] followed them and trained a network using adversarial loss Ladv(x):

where L(x) is the loss function computed on the original image and L(xperturbed) is the loss function computed on an adversarially perturbed image (using e.g. the fast gradient sign method described in our last post) and ɑ is a hyperparameter assigning weights to the components of the adversarial loss function.
Multiple improvements have been proposed to the regular adversarial training. For example, Harini et al. [6] added an adversarial logit pairing component to the loss function, which encourages the logits (outputs from the network before applying softmax normalization function) obtained from two images (original and adversarial) to be similar. The intuition behind this idea is that both clean and perturbed versions of the same example should be assigned to the same class so big differences between their logits are penalized.
Feature denoising
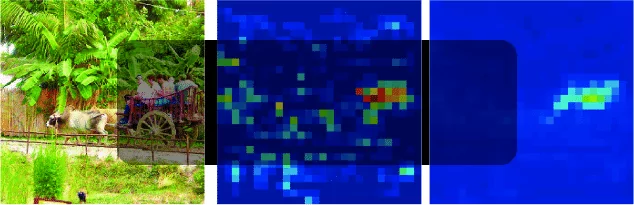
Xie et al. [5] recently proposed another method of defense against adversarial attacks, namely, feature denoising. Authors showed that while adversarial perturbations are often barely perceptible in the pixel space, they cause a significant noise in the feature maps. As the image is passed through the network, the perturbation increases and not-existing activations of the feature maps arise, which leads to wrong predictions.
Below feature maps of original and perturbed images are presented:

Based on this observation, the authors developed a new method of defense against adversarial attacks, namely, they added multiple blocks for feature denoising to the neural network and trained it end-to-end on adversarial examples.
The authors utilized ResNet [7] with 4 denoising blocks. Below adversarial images are presented, together with the feature maps before (left) and after (right) applying denoising:

As can be seen, noise is substantially reduced as a result of denoising operation. Adding feature denoising during adversarial training improved the accuracy of classification on adversarially attacked images. The method won first place in the Competition of Adversarial Attacks and Defences (CAAD) 2018 [8].

To sum up
Neural networks’ vulnerability to adversarial attacks casts doubt on their usability in the real-world environment, especially in safety-critical systems, like for example autonomous cars and medicine. Thus finding an effective defense strategy is of great importance.
However, there are a few challenges that we have to face when applying the defense method. For example, weak performance on adversarial examples produced with attack approaches that haven’t been used during adversarial training is a common issue. Additionally, drop in classification accuracy on unperturbed images may happen.
Literature
[1] Szegedy, Christian, et al. “Intriguing properties of neural networks.” arXiv preprint arXiv:1312.6199 (2013)
[2] Madry, Aleksander, et al. “Towards deep learning models resistant to adversarial attacks.” arXiv preprint arXiv:1706.06083 (2017)
[3] Xie, Cihang, et al. “Mitigating adversarial effects through randomization.” arXiv preprint arXiv:1711.01991 (2017)
[4] Das, Nilaksh, et al. “Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression.” arXiv preprint arXiv:1705.02900 (2017)
[5] Xie, Cihang, et al. “Feature denoising for improving adversarial robustness.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019
[6] Kannan, Harini, Alexey Kurakin, and Ian Goodfellow. “Adversarial logit pairing.” arXiv preprint arXiv:1803.06373 (2018)
[7] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016
[8] http://hof.geekpwn.org/caad/en/index.html
Project co-financed from European Union funds under the European Regional Development Funds as part of the Smart Growth Operational Programme.
Project implemented as part of the National Centre for Research and Development: Fast Track.




