Deep learning is nowadays one of the most exciting technologies. Over the last decade it has been applied with a great success to various computer vision tasks, such as image classification or object detection. The real breakthrough was in 2014, when a new type of neural networks was introduced, namely Generative Adversarial Networks (GANs) [1], which can be used to generate real-looking artificial data.
Note: this is our first post about generating artificial data with GANs. We conducted more research and obtained better results using CycleGAN.
In the following sections the main idea behind GANs will be presented as well as how we use them at NeuroSYS.
Why use GANs?
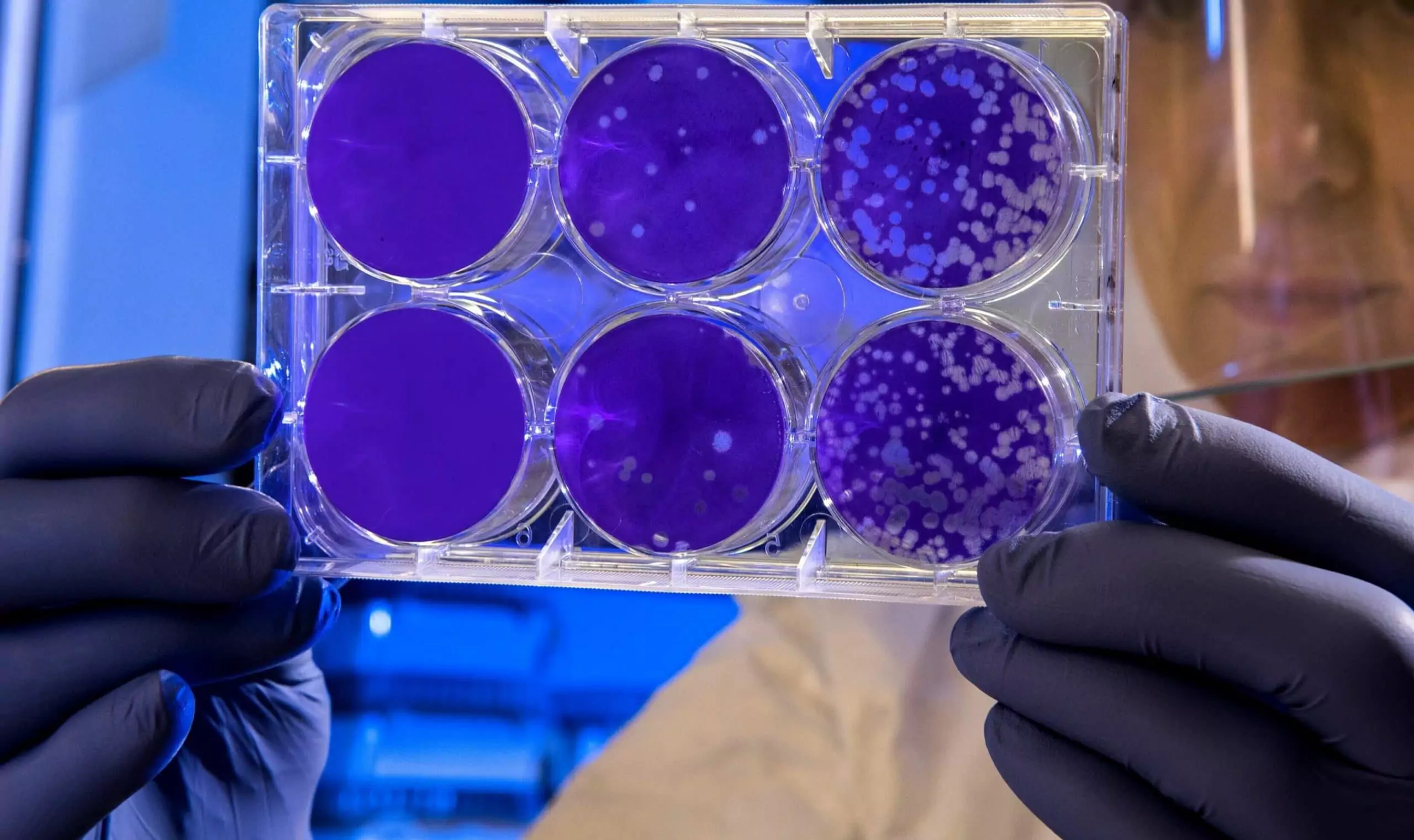
One of our tasks at NeuroSYS is to build an image classifier for distinguishing Petri dishes with bacteria or fungi grown in them from empty ones. Most images in our dataset contain multiple, large organisms, located close to the center of the dish and our classifier can recognize such samples with high accuracy. However, we also have images that contain only few, small organisms near the edges of the dish. Since there is a small amount of such samples, our model cannot learn to correctly recognize them.
Below two types of samples are presented:
 - Part 1 1")
 - Part 1 2")
We applied GANs to produce artificial images of bacteria and fungi in Petri dishes with hope that we will generate more untypical samples.
Generative vs. Discriminative Model
To understand GANs, it is essential to first learn how generative algorithms work and a great way to do that is to compare generative and discriminative approaches.
Suppose that you have pictures of cats and dogs and want to classify them. Given your training set, a discriminative algorithm will try to find a decision boundary that separates cats and dogs. Then, to classify a new picture, it checks on which side of the decision boundary this image falls, and makes its prediction accordingly. In contrast, a generative algorithm first looks at cat pictures and builds a model of what cats look like. Analogously, it creates a separate model for dogs. To classify a new picture we can match it against both models, to see whether it looks more like cats or more like dogs we had seen in the training set.
So a discriminative algorithm only models a decision boundary between different classes while a generative algorithm models the actual distribution of each class. Both models can be used for classification, however a generative model can do much more than that, namely it can be used to generate new instances of a class, for example new pictures of cats and dogs. GAN is an especially powerful type of generative models.
 - Part 1 3")
How GANs work?
GAN consists of two neural networks competing against each other (hence the word “adversarial”). One network, called generator, generates new instances of data, for example images. The second network, called discriminator, evaluates them, i.e. it decides whether the instance belongs to the original training set or have been generated by the generator. The goal of the discriminator is to correctly recognize fake and authentic data instances while the generator aims at creating data instances, that will be deemed authentic by the discriminator. The hope is that during training both networks will get better and better, with the end result being a generator that produces realistic data instances.
The process is depicted in the figure below:
 - Part 1 4")
In practice, when GAN is applied to visual data as images, the discriminator is a Convolutional Neural Network (CNN) that can categorize images and the generator is another CNN that learns a mapping from random noise to the particular data distribution of interest.
Real-world examples
As stated above, at NeuroSYS we applied GANs to produce fake images of bacteria and fungi in Petri dishes. We aimed at creating samples that we lacked in the original set, namely images with only few, small organisms located near the edges of the dish. Below we present some generated images and compare them with original ones. Specifically we used a variation of standard GANs called Improved Wasserstein GANs [2, 3].
 - Part 1 5")
 - Part 1 6")
We did not manage to generate real-looking samples. While fake Petri dishes look very realistically, bacteria and fungi on generated images can be easily distinguished from the original organisms. The reason may be the fact, that the Petri dishes are large structures, present on every image. In addition, all Petri dishes in our training set are similar. Bacteria and fungi are much smaller and differ significantly in terms of size and appearance. Moreover they are not present on every image. We need more data for GAN to learn all the features of bacteria and fungi and create real-looking samples.
On the other hand, our GAN generates organisms of various sizes, both close to the center of the Petri dish and near the edges. If generated organisms were more similar to the original ones, we would be able to produce needed samples.
To sum up
GANs are an extremely powerful tool for generating artificial data and impressive results have been achieved on standard datasets used in machine learning. However it can be hard to successfully apply them to the real-world problems. We are looking forward to conduct more experiments and hope to produce real-looking samples in the future.
References
[1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, Generative adversarial nets, Advances in neural information processing systems, pages 2672–2680, 2014
[2] M. Arjovsky, S. Chintala, and L. Bottou, Wasserstein gan, arXiv preprint arXiv:1701.07875, 2017
[3] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville, Improved training of wasserstein gans, arXiv preprint arXiv:1704.00028, 2017
Project co-financed from European Union funds under the European Regional Development Funds as part of the Smart Growth Operational Programme.
Project implemented as part of the National Centre for Research and Development: Fast Track.
 - Part 1 7")